1.3.2 tcp Race Condition in 2.0.36 kernels
The client is a 2.0.36 machine. The tcp race condition in the 2.0.x kernels has a different origin to the 2.2.x kernels and has not been properly fixed (the race condition was only discovered as the 2.2.x kernel was being released and now people have moved onto the 2.2.x kernels).
- unpatched 2.0.36 client - patched 2.2.14 director, jagged line shows problems with tcpip layer.
- patched 2.0.36 client - patched 2.2.14 director, tcpip race patch reduces but does not eliminate problems with tcpip layer.
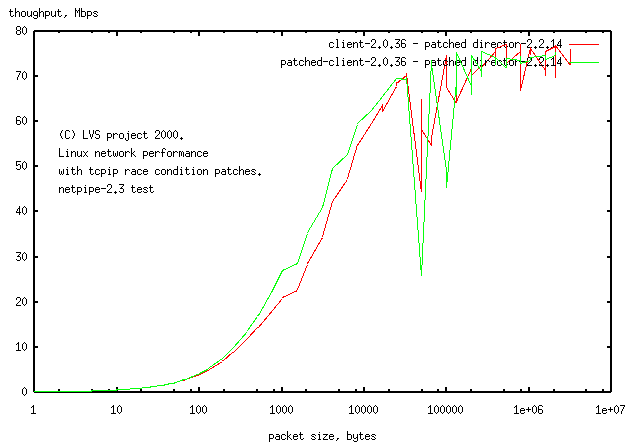
The partial fix does increase network performance. The network performance drops only for data packet just larger than 64k, presumably a limitation in the 16bit buffer size for ethernet packets. Any network limited performance curves for packets which take the path connecting the client-director should show the jaggies for packets >64k
Note the higher network speed (75Mbps) for this client-director link, compared to 45 Mbps for the director-realserver link (previous image). Presumably this is due to the higher CPU speed of the client (133MHz) compared to the realserver (75MHz).
1.4 effect of mtu on netpipe test
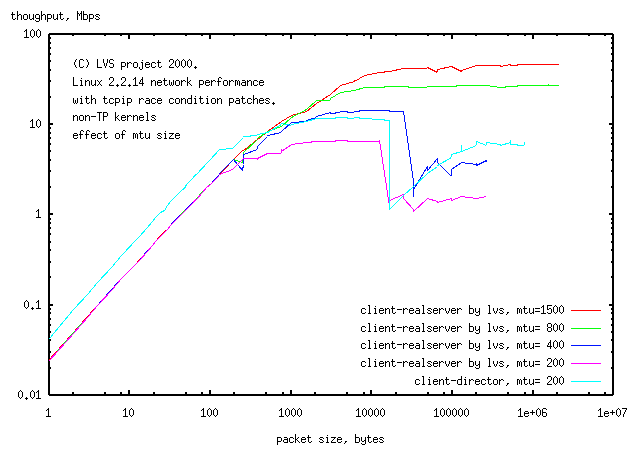
The netpipe curve for the simple LVS on a log-log scale has a pole at ca. 1500bytes (assymptotes of slope 0 and 1, intersecting at 1500bytes). The pole is near enough to the mtu default of 1500bytes suggesting that the pole is caused by the mtu. One possible interpretation of this is that the cost to assemble, transmit and receive files is the same for all file sizes <1500bytes. To test whether the mtu is responsible for this feature of the netpipe curve, the mtu on the client of the simple LVS was varied.- mtu=1500
- mtu=800
- mtu=400
- mtu=200
Unexpectedly, at large packet sizes, throughput dropped sharply for small mtu: mtu=400 and mtu=200. Tests of all the nodes invoved (client, director, realserver, results not shown) showed that netpipe tests to self (effected by changing the mtu on lo) behaved normally (pole moves to lower value with decreasing mtu, accompanied by a corresponding decrease in throughput, normal throughput at large packet sizes). Only pairwise tests (by changing mtu of eth0) showed collapse of throughput at small mtu. The pairwise data shown is client-director mtu=200. The problem is not with LVS but with the network layer. It might be useful make sure this problem is not occuring on your production setup.
It is not clear whether the collapse of performance at large packet sizes with small mtu's is an indication of a deeper problem that will affect an LVS running with the standard mtu=1500.
caveat:It is not possible to quantitate this test.
When the 2 netpipes are run
"simultaneously" from the same host,
the 2 processes are
Results:
Netpipe runs interfere with each other.
The curve of
throughput to client
is lowered
in the presence of another netpipe process.
The same thing happens for the
throughput to realserver
which runs more slowly for
in the presence of another netpipe process.
Note that the interference in
client netpipe process
is small at medium throughput. This is likely because the slower
realserver netpipe process
was running at small throughput when the
client netpipe process
was operating at midrange throughput.
However when the
realserver netpipe process
was at midrange throughput, the faster
client netpipe process
was operating at high throughput and so a speed
decrease is observed at midrange throughput for the
realserver netpipe process.
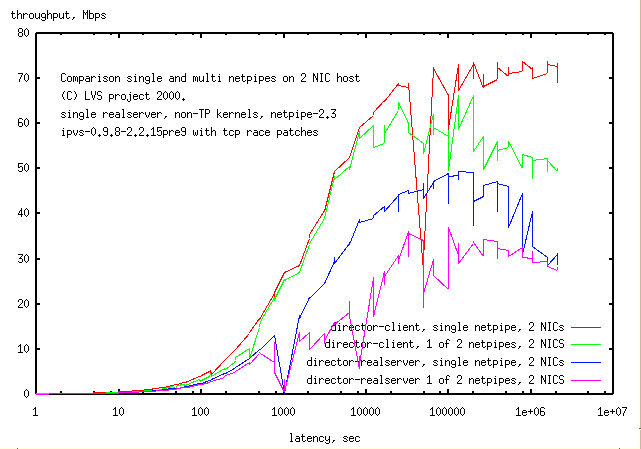
Results: The throughput on the director-client
link (the faster link:
red, green)
dropped when the network was changed from
2 NICs to 1 NIC,
while that on the director-realserver
(the slower link:
blue, magenta
increased on going from
2 NICs to 1 NIC.
Presumably the total throughput did not change much.
I expected a decrease in throughput on both links here.
It would seem that the tcpip stack is the limiting
process. Presumably with a faster CPU capable of feeding 2 NICs
at full speed, the results might be different.
Presumably if the tcpip stack
was capable of feeding 2 NICs at 100Mbps each and if the test was
changed to make both links through 1 NIC, then the throughput would be a
half.
This appears to be tcp problem rather than an LVS problem. However it would be
good to test your setup to make sure you don't have this problem.
Method:
The network performance is compared for
The connection client-director
is fastest presumably because of the higher
speed of the cpus involved.
The separate links:
The direct connection from
client(2.0.36)-realserver is slower at high network load
than the
director(2.2.14)-realserver connection.
The hardware in the two cases is the same, the only difference is the kernels -
presumably the uncorrected tcp race condition (seen in the jaggies
at high load on the client-director line) is responsible.
Connection by forwarding:
The connection
client-forward-realserver by forwarding through the director
is slower at low network load by 20% than is the
direct connection -
the 20% performance hit presumably is due to the latency of the extra 2 NICs
and the overhead of the extra host in the path.
At high network load, there is no difference -
presumably the network becomes rate limiting.
Connection by LVS:
There is no difference in network performance in the
client-realserver connection whether by
lvs through the director
or by forwarding through the director.
The director has little discernable load (as seen by load average or cpu usage)
when the network is at highest load (client and
realserver have 80% cpu running netpipe and high load averages).
Here's the conf file for VS-TUN. The only changes from the VS-DR setup
are the LVS_TYPE and the SERVER_VIP_DEVICE.
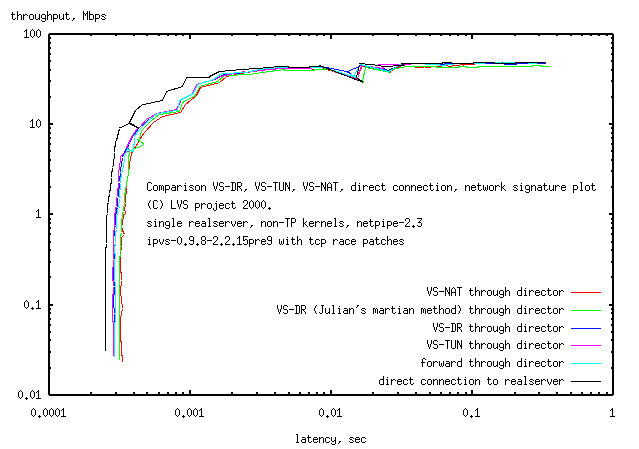
Results:
The lowest latency connection between the client and the realserver
is the direct connection.
Connection through the director (ie adding 2NICs to the packet path) gives the
same signature curve for
forwarding
VS-TUN
and
VS-DR.
VS-NAT has a 15% latency penalty over
VS-DR
and VS-TUN
indicating that for small packets,
VS-NAT
will have a corresponding decrease in throughput.
For large packets the throughput is the same for
VS-NAT
and the two lower latency methods
VS-DR and
VS-TUN.
The director was a lot busier with
VS-NAT
(50% system CPU with "top") at high throughput
than either
VS-DR (5% system CPU)
or
VS-TUN (5% system CPU)
and the
keyboard and mouse were quite sluggish.
The value of the added latency from
VS-NAT (about 50usec) is similar to the value of
60usec from Wensong and limits throughput on a director on a 576byte mtu to 72Mbps
and a 1500byte mtu to 200Mbps. The hardware, rather than
VS-NAT, limits
throughput to about 50Mbps.
Julian's martian modification of VS-DR
in which the director is the default gw for
for the realservers (and packets pass in both directions through the director, rather
than only the inbound packets in
VS-DR), had a greater latency than with
VS-DR,
but better latency than with
VS-NAT.
Unlike
VS-NAT
, but like VS-DR,
there was no load on the director at maximum throughput.
The netpipe test with the realserver running by TP aborted several times with
the LVS'ed service (netpipe) in a FIN_WAIT state (ie netpipe could no longer bind to
its socket). Whether this is a problem with TP is not clear yet.
The kernels for director, realserver were
Result: There is no change in throughput when only one node
has a TP kernel
(TP, non-TP), (non-TP, TP) .
It's not till TP is put on both kernels (TP, TP),
that throughput is affected and then only at high network load.
Presumably there is some interaction between the two TP kernels at high network load.
Here's the conf file
Result:
Compared to the
standard non-TP VS-DR setup
(same curve as in 3.2 above)
adding
TP to the kernel in the realserver,
but otherwise not changing the LVS setup
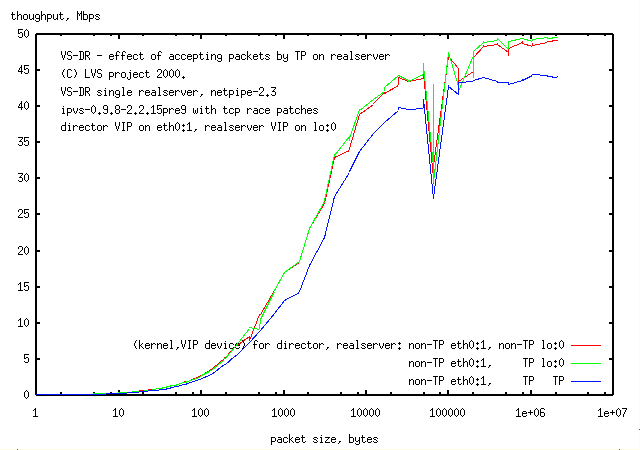
(ie leaving the VIP as lo:0), had no effect on network speed.
However,
accepting packets by TP
dropped network speed by 10% at high network load and ca. 25%
at mid and (not seen here in the lin-log plot here) low network load.
Here's the conf file
Result:
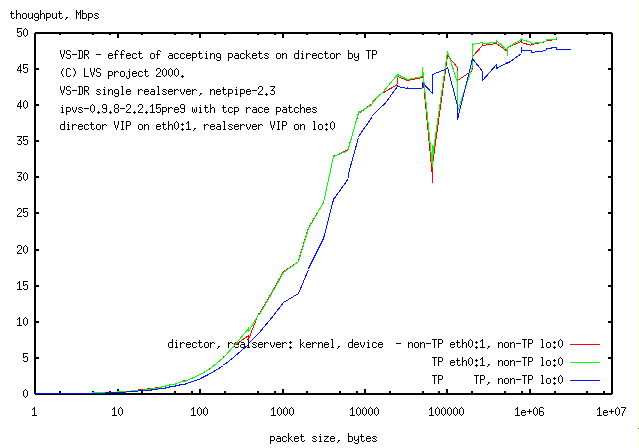
Compared to the standard VS-DR setup
adding TP to the kernel in the director,
but otherwise not changing the LVS setup (ie leaving the VIP as eth0:1),
had no effect on network speed
(as seen in 3.2 above).
However,
accepting packets by TP on the director
dropped throughput by ca. 25% at mid and (not seen in the lin-log plot)
low network load while having little effect at high network load.
Interestingly the jaggies, with packets just bigger that 65kbytes associated with
the tcp race condition, does not
happen with the director accepting packets by TP (where packets
are accepted by the lo rather than eth0). This loss was presumed
(Section 1.3)
to be caused by the 2.0.36 kernel on the client,
but apparently the director's eth0 is involved too.
Here's the conf file
Compared to the control of accepting packets by
ethernet device on both director and realserver,
accepting packets by TP on
Result:
Here's the conf file
Result:
Comparison of netpipe and ptester
The decrease in transfer speed for the 64Mbyte file (compared to the 32M, 16M... files)
is presumably because it cannot fit in 64M of memory in the realserver
and is being read off disk.
The hit rate curve for http shows that high hit rates
are only possible for small files.
Watching the switch lights during these tests, for small file sizes, transfer
would stop for noticable periods during the test
(on 8-12 occassions during the 1 minute test). Ptester returns not only the
average transfer speed, but the minimum and maximum.
Inspection of the ptester output showed that most transfers were taking 5msecs,
but some were taking 300msecs for the same file. The
Result:
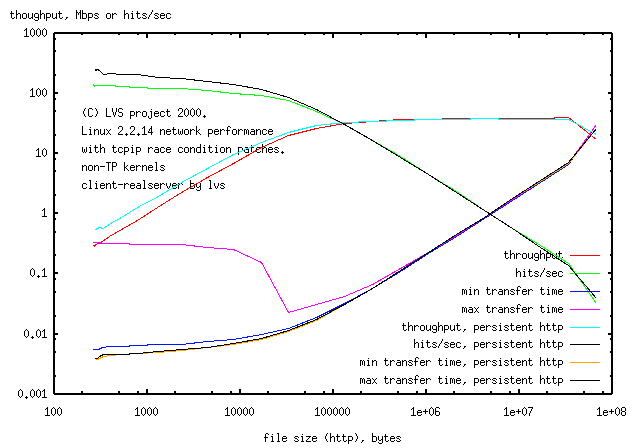
The
maximum transfer time for persistent connection
was now only about double that for the
minimum transfer time
rather than 100 times greater
(cf max transfer time for non-persistent connection,
min transfer time for non-persistent connection).
Throughput at low netload was double for
persistent http compared to
non-persistent http.
This is reflected in hits/sec for small file sizes for
persistant http being doubled compared to
non-persitent http. The lights on
the switch did not stall during file transfer as they did for non-persistent
connection. It would seem that the stopping is associated with setting up
(or breaking down) tcp connections, but I have no idea why this process
halts occassionally for 300msec.
The conf file used was the same as the http conf file, substituting http with ftp.
Result:
Comparing
Similarly
And
However
It is clear that there is no performance improvement with 2 realservers
The reason for this is that the requests are serialised.
Watching the lights on the switch for the larger file transfers,
the light for one realserver would flash for several
seconds, while the light for the other was fixed. Then the roles would change.
ptester is designed to make serial requests to the webserver, or to make
serial persistant connections to the webserver. It is not designed to make
simultaneous connections to the multiple instances of an httpd that
can run on a webserver (or appear to exist on an LVS).
There are several aspects to the problem of measuring performance of an LVS.
The problem of synchronising multiple clients is not simple.
My first attempt with this approach used multiple netpipe clients on
a single client machine connecting to a 6-way LVS. The runs took a minute
or two and it was relatively simple to start the multiple
netpipe clients within a few seconds of each other. Throughput measured
by adding the results from individual clients was
125Mbps on 100Mbps ethernet, which I posted to an
incredulous and amazed mailing list in Jan 00.
Discussion with
Guy, the netpipe maintainer
revealed that netpipe spends some time doing calculations and before incrementing
the packet size for the next test, probes the network for throughput
to determine the number of repetitions for that packet size.
This quiesent netpipe process
is not using the network, allowing other netpipe processes to throughput
at a higher speed. If netpipe is to be used to test a multi-way LVS, each
run of a certain packet size will have to be synchronised. It was this
result of 125Mbps throughput
that convinced me of the need to characterise the simple LVS first.
This reasoning would suggest that LVS's be tested with ftp and http, and not with
the netpipe, which sends large byte streams in both directions. The
poles in the netpipe and http tests
suggest that assembling packets costs the same no matter how large or small the packet
and that the LVS is likely to work with services in which the packet
sizes are the reverse of http and ftp, ie request packets are large
and replies small (eg ACK).
Method:
The simple LVS was tested with
Result:
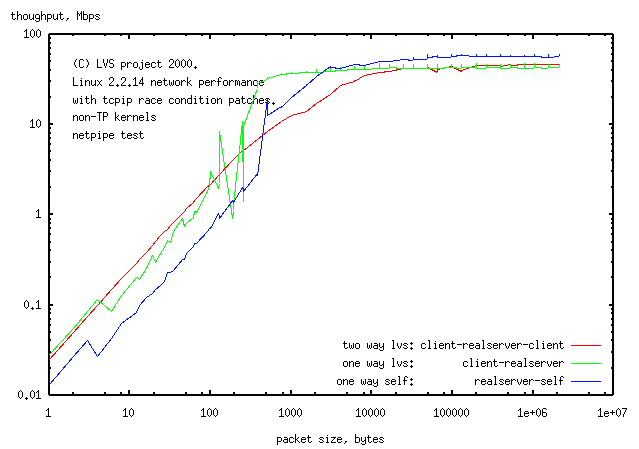
During the netpipe one way (streaming) test, the
load average and CPU usage on the client and realserver was high, but was undetectable
on the director. This is the same as happens for the http test (where the big packets are
going in the opposite direction).
The bumps in the one way lvs test rather than the smooth
curve of the standard two way lvs netpipe test
indicate problems. The one way tests for 2 of the 3 machines involved
(client, director and
realserver) to self, had similar
problems showing that the problem is not with LVS but with the nodes.
Although the results are not clear,
it appears that the netpipe one-way stream test give the
same throughput and node position as does the two-way netpipe test,
indicating that LVS has
no preference for the direction in which the large packets travel
in an assymetric service.
Method:
The simple LVS was tested by copying files from the client to the realserver with rsh.
The files were written to /dev/null or to /usr on the realserver, to determine the
effect on transfer rate of disk activity on the realserver.
Make sure you can do a copy directly to the realserver from the command line first -
the realserver must have an entry in ~user/.rhosts like
Here's the conf file
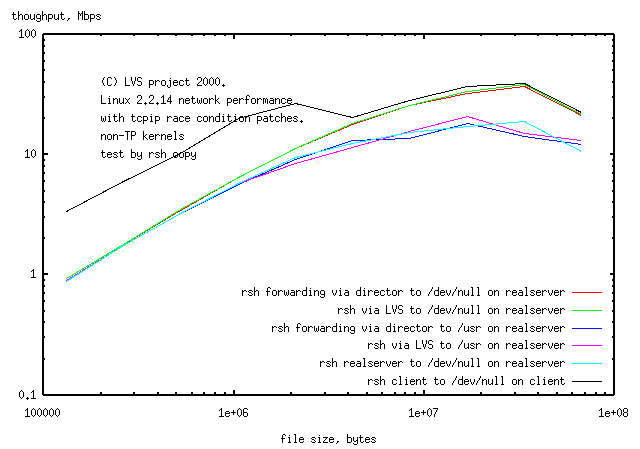
Throughput reaches 40Mbps for
copy to /dev/null on the realserver by forwarding and for
copy to /dev/null on the realserver by lvs. At high
throughput the client was runnign 90% CPU with rsh, the realserver 40% CPU with
cat, while the director had no detectable change in the process table. The
dropoff in throughput for the 64M file is the same as seen for
transfer by http and is because the file is too large to
fit into memory and has to be read from disk.
LVS then is equally suitable for services which tranfers large packets to a realserver
as those that return large packets from a realserver.
Transfer to a disk (/usr) on the realserver is slower for large (>128k) files,
presumably slowed by disk activity on the realserver.
rsh directly to the realserver
reaches 12Mbps, rather than
45Mbps, the limit for this system.
rsh directly to the realserver runs at the same
throughput.
Watching the lights on the switch, halting was seen in the transfers as was
seen with ptester. Using averted vision to watch both the switch and disk
lights, the halts seemed to occur when the realserver was writing to disk.
In an attempt to determine the source of the high latency (1.1sec)
test were done
rsh copy on 133MHz client to self, latency=0.3sec
and
rsh copy on 75MHz realserver to self, latency=1.1sec.
The max throughput on the realserver to /dev/null was the same as for the LVS
copying to disk on the realserver, ie one of the components of the LVS was slower
than the LVS itself - this may be because the realserver when copying to self
is running both cat and rsh processes and is more cpu bound.
There's no explanation for the latency of rsh.
Method:
LVS was tested for printing using the client
rlpr.
A print queue was set up
on the realserver with the printing device=/dev/null with the printcap entry
Printing to multiple servers (either to the realservers by forwarding
throught the director, or by LVS'ing through the director) was done by
running multiple rlpr jobs in background on the client from a bash script
and using the wait $pid command to signal the end of the job for timing the print run.
Here's the conf file
Since you don't have a physical printer on the realserver, you can check for printfiles
arriving by
Result:
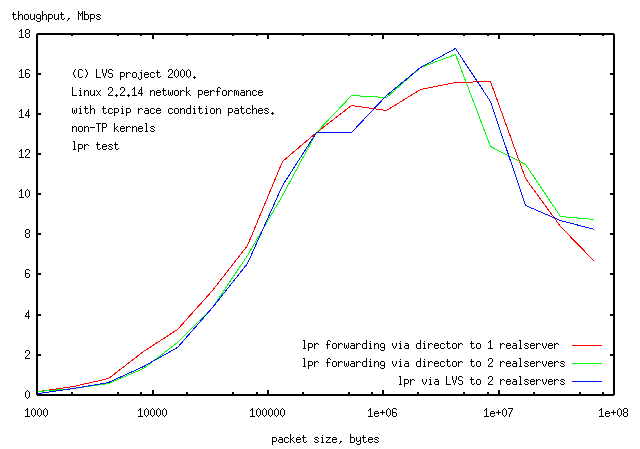
Pre-reading the printfile on the client does not help throughput (unlike the httpd case).
From watching
output from echo statements from the script, the client's disk light and the
switch lights, it appears that the rlpr client
reads the file off the disk again before sending it to the remote lpd.
The result of this is that rlpr has the same serialisation problems as does
ptester for httpd - there is no real difference in throughput for
Although this is not a demanding test of printing by LVS, it is likely that printing
will be limited by the physical printer mechanism and disk access,
rather than the network.
The director in an LVS can handle 50Mbps of netpipe with little increase in loadaverage.
Presumably it will be able to handle printing the same level of throughput.
The ramdisk is setup (thanks to Jerry Glomph Black) by doing
Here's realserver:/etc/exportfs
Here's client2:/etc/fstab
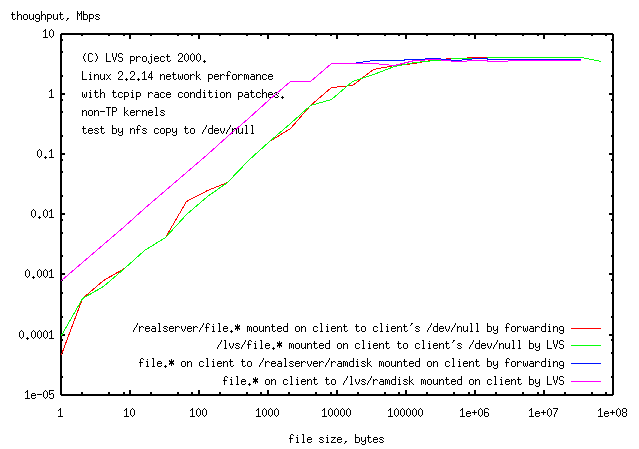
Result:
While latency is lower copying to the ramdisk (presumably copying to /dev/null
which is seen using CPU in "top" adds to the latency), nfs in both
directions has the same speed and is the same for mounting by lvs or by forwarding.
The speed is quite low (4Mpbs), barely more than direct writing to disk.
Interestingly no Activeconnections were seen by ipvsadm when running lvs, although
a small number of Inactiveconnections were seen.
Joseph Mack
24Jun00
1.5 Number of NICs/networks in LVS
It is possible to set up an LVS with different numbers of NICs on each host.
The router/client can have 1 NIC to the director and 1 to each realserver(s),
the director can have 1..(realservers+1) NICs and the realservers can have
1 or 2 NICs. (The cost of 100Mbps network hardware is small enough that
the costs of extra NICs is not a consideration in setting up an LVS.)
Presumably more NICs will lower congestion on each network at the cost of
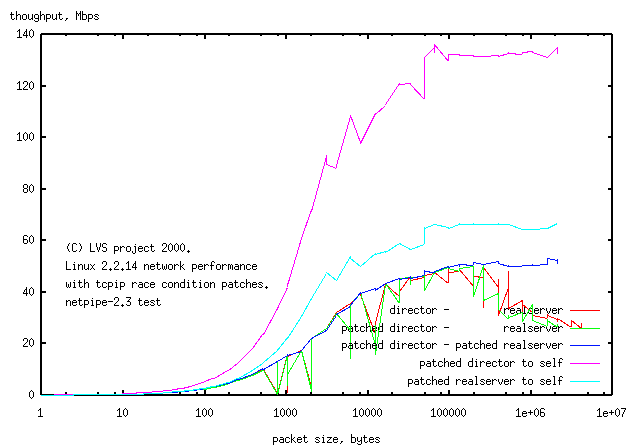
more routing in each host.1.5.1 Tests on the Hardware
Here are tests on the director's hardware to see how it handles netpipe
tests through 1 and 2 NICs.
I was looking for any interference
in throughput on one of the links when netpipe was run on the other.
1.5.2 Netpipe from a 2 NIC host
Method: Netpipe on the director connected to
1.5.3 Netpipe from a 1 NIC host
To determine the effect of the number of NICs in the previous test above, the
multi-netpipe tests were rerun with 1 NIC on the central host (and compared
to the 2 NIC results).
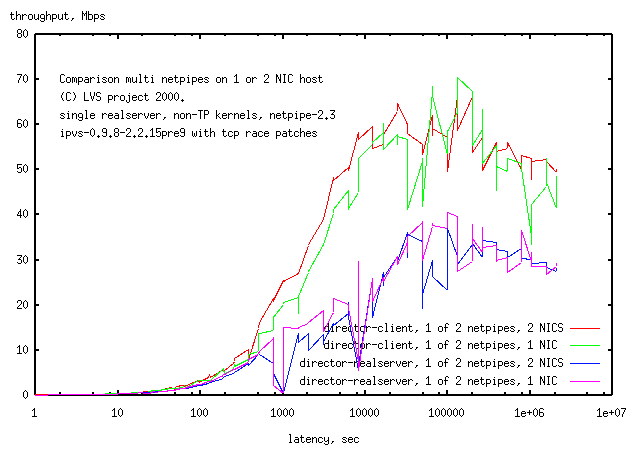
1.5.4 LVS with 1 or 2 NICs
Method:
The 2 NIC VS-DR network was setup with
#lvs_dr.conf, 2 NICs on director, 2 NICs on client
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #to test that the LVS works
SERVICE=t netpipe rr realserver1 #the service we're interested in
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#end lvs_dr.conf
A 1 NIC VS-DR network was constructed by downing eth1 on the director and
eth0 on the client. The only difference in the conf file is the device
for the VIP on the director (eth0:110 rather than eth1:110)
#lvs_dr.conf, 1 NIC on director, 1NIC on client
#all NICs on 192.168.2.0/24 are down
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth0:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client
SERVICE=t telnet rr realserver1 realserver2 #to test that the LVS works
SERVICE=t netpipe rr realserver1 #the service we're interested in
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#end lvs_dr.conf
Results:
The 1 NIC LVS
has jaggies in the throughput plot at low throughput, while the
2 NIC LVS has a smooth transfer curve.
The jaggies look like
tcp race condition problems (the client is running a 2.0.36 kernel with
a poorly handles tcp race condition). Watching the lights on the switch
for the
1 NIC LVS
I could see the
network stop every few seconds and then start again.
The drop at high throughput for the
1 NIC LVS
would normally be due
to collisions, but is not likely to be the cause here, since there is
only a single netpipe process running.
The return packet in netpipe is a reply to the original packet
and both packets are not going to
be on the net at the same time.
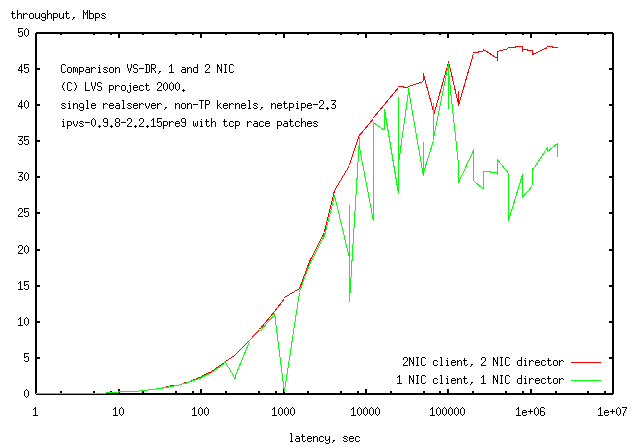
2.0 VS-DR LVS performance compared to forwarding
Summary: LVS has the same network performance as forwarding for the
case of one realserver.
(Hopefully it will be the same for a large number of realservers
but we haven't done the tests yet).
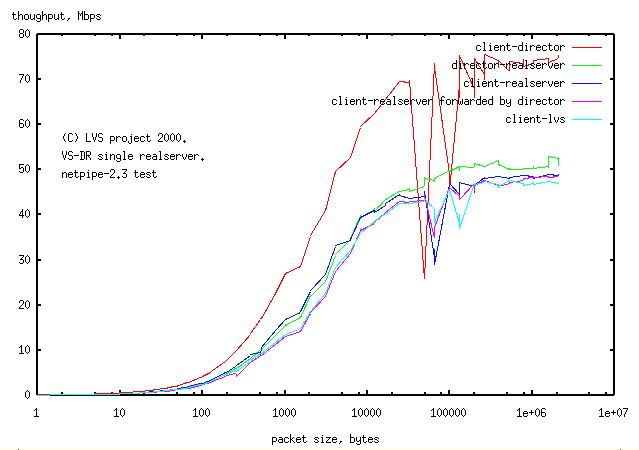
2.1 Comparison of VS-NAT, VS-DR, VS-TUN, forwarding and direct connection
Method:Netpipe was used to compare throughput for
and were graphed using the netpipe "signature" plot to show the network latency.
#lvs_tun.conf
LVS_TYPE=VS_TUN
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2
SERVICE=t netpipe rr realserver1
SERVER_VIP_DEVICE=tunl0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_tun.conf------------------------------------
Here's the conf file for Julian's martian modification of VS-DR.
#lvs_dr.conf (C) Joseph Mack mack@ncifcrf.gov
LVS_TYPE=VS_DR
INITIAL_STATE=on
#note director needs 2 NICs. VIP must be on outside NIC.
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2
SERVICE=t netpipe rr realserver1
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
#note gw is director not router
SERVER_DEFAULT_GW=director-inside
#----------end lvs_dr.conf------------------------------------
3. Transparent proxy (TP)
3.1 Introduction
The standard method of setting up a VS-DR realserver requires the
VIP on a non-arping lo:0 device.
Horms
found another solution to the "arp problem"
in which the realserver accepts packets for the VIP by transparent proxy
(see
arp write up on LVS site ,
the mailing list, next HOWTO or next configure script for setup details).
Using transparent proxy, the realserver
does not require a device with the VIP (eg lo:0, dummy0) to work with VS-DR.
Instead the packets are sent directly to the NIC on the realserver
by the routing table maintained by LVS in the director.
It is also possible to have the director accept packets by transparent proxy.
In this case also there is no VIP on the director and you have to arrange for
packets for the VIP to be routed to either an IP or a MAC address on the director.
Tests of performance compared to the non-arping lo:0 method gave conflicting results.
Horms suspected that just adding transparent proxy to the realserver kernel
slowed network performance even if transparent proxy was not being used.
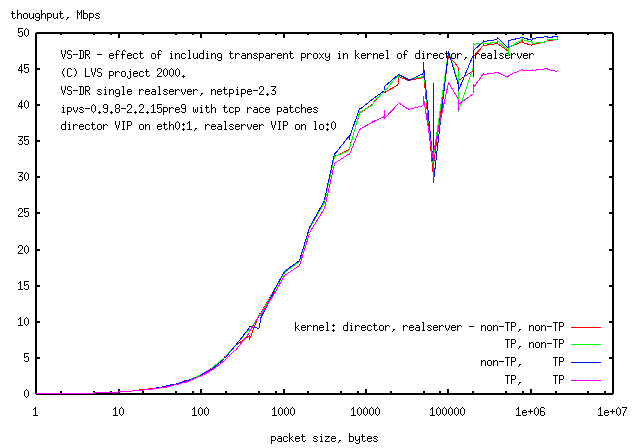
3.2 effect of TP in the kernel of director,
realserver in VS-DR using an non-arping lo:0 for the VIP
Method:
The test was only to measure the effect
of adding TP to the kernels on the director and realservers.
A standard VS-DR LVS was used for the tests
(packets were accepted by the ethernet devices and not by TP
- the director VIP on an arping eth0:1
and the realserver VIP on a non-arping lo:0).
3.3 Accepting packets on the realserver by TP
Method:
A 3 node VS-DR LVS (client, director, realserver)
with the director VIP on an arping eth0:1 device was tested with netpipe.
The realserver had either a non-arping lo:0 device or transparent proxy for the VIP.
The director has a non-TP kernel, while the realserver was tested with both kernels.
#lvs_dr.conf for TP on realserver
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
SERVICE=t netpipe rr realserver1 #the service of interest
#note realserver VIP device is TP
SERVER_VIP_DEVICE=TP
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
On the realserver, the (kernel type, VIP device) was -
3.4 Accepting packets on the director by TP
Method:
A 3 node VS-DR LVS was tested with netpipe.
The realserver has a non-TP kernel with the VIP on a non-arping lo:0.
The director accepted packets for the VIP either by standard arping eth0:1 device
or by transparent proxy.
#lvs_dr.conf for TP on director
#you will have to add a host route or equivelent on the client/router
#so that packets for the VIP are routed to the director
LVS_TYPE=VS_DR
INITIAL_STATE=on
#note director VIP device is TP
VIP=TP lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
SERVICE=t netpipe rr realserver1 #the service of interest
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
On the director, the (kernel type, VIP device) was
3.5 Accepting packets on both director and realserver by TP
Method:
Netpipe tests were run on the simple LVS with TP kernels on both director and realserver.
The director and realserver accepted packets by TP or regular ethernet device.
#lvs_dr.conf for TP on director and realserver
#you will have to add a host route or equivelent on the client/router
#so that packets for the VIP are routed to the director
LVS_TYPE=VS_DR
INITIAL_STATE=on
#note director VIP device is TP
VIP=TP lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
SERVICE=t netpipe rr realserver1 #the service of interest
#note realserver VIP device is TP
SERVER_VIP_DEVICE=TP
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
Result:
(Note: the control for this test, with
TP kernels on both machines, eth0:1 and lo:0 device
is slower by about 10% at high network loads than with
non-TP kernels at high network loads
(there is red curve).)
lowers network throughput at low network loads
(or small packet sizes can't tell which yet) by ca. 25% while
increasing it marginally at high network loads.
Once you accept packets by TP on one of the machines,
accepting packets on the other node by TP incurrs no further speed penalty.
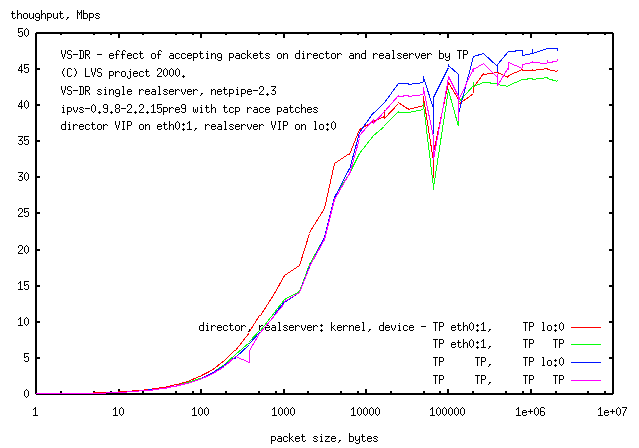
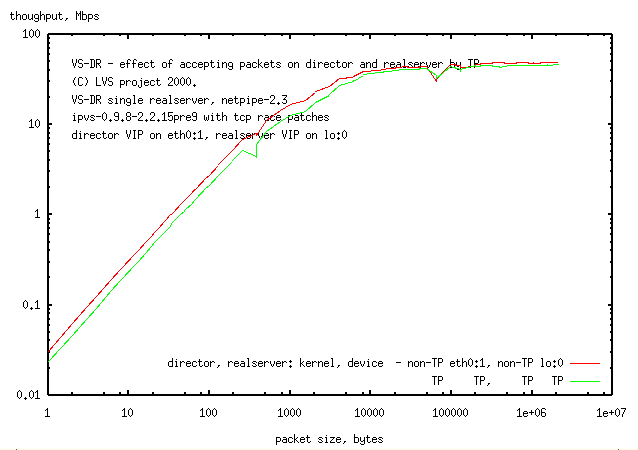
3.6 Comparison of maximally TP LVS with fully ethernet device LVS
Method: netpipe was used to test an LVS with TP kernels
and which accepted packets by TP on both the director and the realserver,
and compare it to an LVS with non-TP kernels and which accepts packets
by ethernet devices.
The network performance is 30% lower at low network throughput (or small
packet sizes, we don't know which yet) with a small change at high network load
(presumably when you need the LVS the most). This decrease in performance
may be acceptable in some situations if the convenience of TP setup is required.
This decrease in speed is due to an increase in latency from TP.
4. Tests with sizeof(reply)>sizeof(request)
Netpipe is a 2 way test with equal traffic in both directions
between the client and the LVS.
However some services (eg http) send small reqests to the server (eg GET / HTTP)
and get back large replies (contents of "bigfile.mpeg").
The number
of packets in both directions are the same, but in the httpd case,
the director is receiving
small packets (mostly ACKs) while the large reply packets go directly from
the realserver to the client.
Emmanuel got poor results using
ptester
to retrieve small files by http from his LVS.
4.1 Non-persistent http connection
Method:
A series of files with size increasing
by a factor of 2 (1,2,4bytes..64Mbytes, called file.1, file.2 ... file.26)
were retrieved from the simple VS-DR LVS by http using ptester.
(The files were filled with the ascii char '0').
To preload the memory of the server,
so that the file would be retrieved from the realserver's memory, rather than disk,
each file was retrieved once from the server and the results discarded. The file was then
retrieved continuously with ptester for 30sec, initiating a new tcp connnection
(-k1) for each GET, using this following script -
#lvs_dr.conf for http on realserver1
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
SERVICE=t http rr realserver1 #the service of interest
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
#!/bin/sh
HOST="lvs"
for SIZE in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
do
#do it twice to flush buffers
ptester -h${HOST} -t1 -k1 /file/file.${SIZE} >/dev/null
ptester -h${HOST} -t30 -k1 /file/file.${SIZE}
done
#-----------------------------
The throughput or hits/sec were plotted against the size of the returned
packet(s) (the 1 byte file required a packet of 266 bytes).
One interpretation of this is that http packages all files into packages which cost
the same as a 64kbyte file.
The 64kbyte size corresponds to the 16bit length counter for IP packets
(I'm not going to recode the tcpip stack to test this). I don't know why the netpipe
test has a pole at 1500bytes while the http test has a pole at 64kbytes (neither
does the author of netpipe). The consequence
of this is that netpipe is 64k/1.5=40times faster than http for transferring small files.
(in sec) are also shown.
While the curve for minimum transfer time looks well behaved,
the maximum time for repeated transfer of small files is
100times larger than the minimum,
showing problems with transfer of small files. No good explanation for this
stopping of transfer was found. However it is absent when
persistent http is used for transfer.
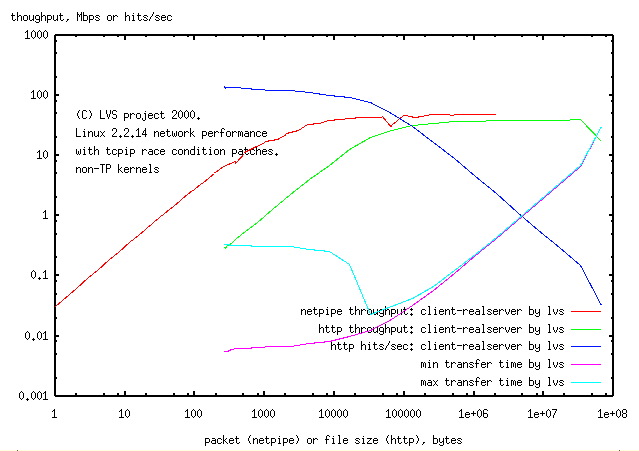
4.2 persistent http connection
Method:
File retrieval by http was compared for persistent and non-persistent http.
On the realserver, apache was set to persistent connection in httpd.conf with
KeepAlive On
MaxKeepAliveRequests 0
KeepAliveTimeout 15
MaxClients 150
MaxRequestsPerChild 300
and the parameter "k1" in ptester increased till the throughput and
hits/sec did not get any faster
(about 1000 for 1byte file, through to 2 for the 64Mbyte file). The LVS setup
was the same as for the non-persistent http case above
(LVS persistence is different to tcpip persistence. LVS persistence
is for port/IP affinity.)
4.3 ftp
Suitable clients for ftp testing were difficult to find. wget writes the
retrieved file to disk, rather than /dev/null. ncftp can save a file
to /dev/null, and would retrieve files directly from the realserver, but
would not retrieve from the realserver via LVS -
the ncftp client would either hang or connect to the
client's ftpd. Under the same conditions the standard console command line ftp
client worked fine.
4.4 Using standard testing tools for an LVS with multiple realservers
Method:An LVS with 2 realservers was tested for non-persistent http by
running ptester from the client with the following script.
#!/bin/sh
#for 2 realservers
HOST="lvs"
for SIZE in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
do
#do it for each realserver to flush buffers
ptester -h${HOST} -t1 -k1 /file/file.${SIZE} >/dev/null
ptester -h${HOST} -t1 -k1 /file/file.${SIZE} >/dev/null
ptester -h${HOST} -t30 -k1 /file/file.${SIZE}
done
#-----------------------------
The only difference from the single server script is that the prefetch is done
twice to put the file into the memory buffer of both realservers.
The graph below compares
the results of a 1 and a 2 realserver LVS.
shows no change in throughput.
are the same.
are the same.
are different - the pathological behaviour is not as bad for 2 realservers. Presumably
this problem will be solved by a change of hardware/software, rather than
by adding more realservers, so this observation is of no use to us.
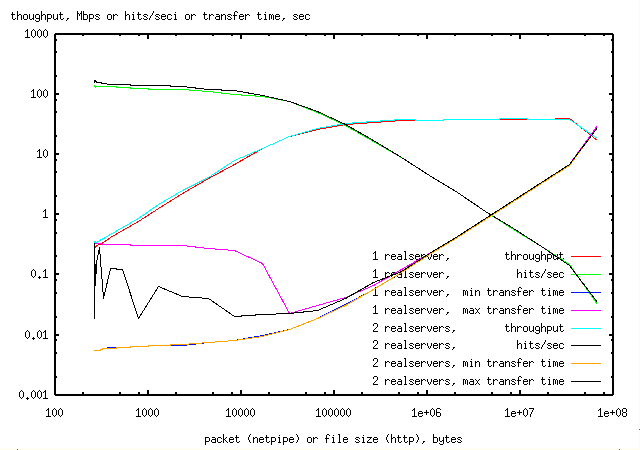
It would appear that test programs need one or both
While this result, that a single serial client will not test an LVS,
is not surprising, I wanted it documented here,
so that people would not try to test LVS scalability with serial
mono-clients.
5. Tests with sizeof(request)> sizeof(reply)
The classical use of VS-DR is for services like http or ftp
where requests are small and replies are large.
The conventional wisdom about an LVS running in VS-DR mode is that the high
scalability depends (among other factors)
on the small size of the inbound packet stream to the director
(the director only handling small inbound packets, eg ACKs)
and on the large size of the outbound packet stream from the realserver
(eg the realserver delivering files in response to ftp or http requests).
The theory then is that one director can direct a large number of
realservers as it offloads much of the network activity to the realservers.
5.1 Netpipe in streaming mode
Netpipe can operate in "stream" mode,
in which the outgoing packets of ever increasing size
receive a small reply (ACK and checksum for the packet received)
rather than the whole packet.
5.2 remote cp with rsh
rsh copies files to a target machine. rsh will test the ability of LVS
to handle services which produce large packet streams from the client, and
which only have small replies.
#lvs_dr.conf for rsh on realserver1
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 lvs
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
#to call rsh by the name "rsh" rather than "shell", use this line in /etc/services
#shell 514/tcp cmd rsh # no passwords used
SERVICE=t rsh rr realserver1 #the service of interest
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
client_machine_name user_name_on_client
The remote copy was executed by this script
#!/bin/bash
#run_rsh.sh
HOST="lvs" #or realserver if connecting directly
for SIZE in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
do
FILE="file.${SIZE}"
echo "file $FILE size $SIZE \n"
#do it twice, first time to flush buffers
#if sending to real disk
rsh $HOST "(cd /usr; cat > $FILE )" <$FILE
time -p rsh $HOST "(cd /usr; cat > $FILE )" <$FILE
#if sending to /dev/null
#rsh $HOST "(cat > /dev/null)" <$FILE
#time -p rsh $HOST "(cat > /dev/null)" <$FILE
done
and the output written to a file by running it with
. ./run_rsh.sh >rsh.out 2>&1
inetd will only allow you by default to spawn 40 processes/min for a particular demon.
Once this limit is reached the demon will no longer be started by inetd.
This is a safety valve to prevent runaway processes.
To allow connections at a higher rate
(eg 100/min) change your inetd.conf line on the realserver to
shell stream tcp nowait.100 root /usr/sbin/in.rshd in.rshd -L -h
Result:
The throughput for small (<128k) files is set by a 1.1sec minimum transfer time.
The position of the pole is then determined by this minimum time
(and the maximum transfer rate). The data for files <128K is not shown.
5.3 lpd
Printing demons accept large files and return only small replies.
An LVS for the service lpd would be useful for distributed printing systems like
Cisco Enterprise Printing System (CEPS)
(originally the
linux-print project),
where both the spooler and the printer can be anywhere in the network (or world)
and any spooler can spool for any printer or for the similar
Common Unix Printing System (CUPS) project.
null:\
:lp=/dev/null:\
:sd=/var/spool/lpnull:\
:lf=/var/spool/lpnull/log:\
:af=/var/spool/lpnull/acct:\
:mx#0:\
:sh:
and here's the contents of /var/spool/npnull
sneezy:/etc# dir /var/spool/lpnull/
total 5
drwxr-xr-x 19 root root 1024 Apr 12 18:50 ../
-rw-r----x 1 root lp 4 Apr 13 12:40 .seq*
-rw-r--r-- 1 root lp 0 Apr 27 22:22 log
-rw-rw-r-- 1 root root 27 May 1 15:58 status
-rw-r--r-- 1 root root 28 May 1 15:58 lock
drwxr-xr-x 2 root root 1024 May 1 15:58 ./
Entries for the client machine were put in hosts.lpd and hosts.equiv and
were checked by printing from the client machine to the realserver(s).
#lvs_dr.conf for lpr on realserver1
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 192.168.1.110
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
#to call lpd by the name "lpd" put the following in /etc/services
#printer 515/tcp spooler lpd # line printer spooler
SERVICE=t lpd rr realserver1 #the service of interest
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
At the server, the file to be printed is written into /var/spool/lpnull
while lpd scans the directory at intervals looking for printjobs. When lpd finds a file
ready for printing (ie unlocked),
in this case the file just disappears (it gets piped to /dev/null).
Presumably an LVS director on a 100Mbps network could direct print
spoolers printing at a
total of 100Mbps.
Unlike http and ftp, printing at the server end is disk-, rather than network-bound,
as the file has to be written to the server's disk before printing.
To prevent the client's disk read being a limiting factor, the file to be printed
was loaded into the client's memory by printing to some (any) machine
and discarding the results just before the test, or else cat'ed to /dev/null.
$netstat -an | grep 515
The throughput for small jobs is determined by
the minimum time to setup and pulldown the connection, about 0.2sec. The throughput is
about 1/3 of that for http or netpipe, presumably limited by disk access. The throughput
is marginally better for disk limited rsh (18Mbps compared to 12Mbps)
resumably because of the smaller setup time for the connection
(0.2sec compared to 1.1sec).
LVS using a udp service; NFS
It would be useful to test nfs file transfer in both directions client-to-realserver
and realserver-to-client. To prevent the slowdown inherent in disk access,
the target should be /dev/null and the source should be from cached memory following
a previous read. There were problems with this with nfs.
Some attempts were made to optimise nfs transfer speed, but despite
statements in man (5) nfs, where the recommended rsize and wsize are 8k, no
difference was seen in latency or throughput for these values between 1-16k (parameters
were changed in /etc/fstab, the filesystem remounted and the tests run again).
(Data not shown).
after a first read from the realserver to client:/dev/null,
the second read occurs at about 300Mbps, ie faster than the 100Mpbs network.
Apparently the file is being cached on the client end.
This did not happen with the other tests described here.
The solution was to flush the buffers on the client by
copying a file bigger than memory to /dev/null between the
first and second file transfer from the realserver to the client.
(This also flushes the nfs code to swap, although apparently with
little increase in latency for the copy).
From the lights on the switch, at least for the 32M file,
all of the file is read from memory on the realserver
as disk activity is absent during the second transfer.
no data is transmitted over the network
(the lights on the switch feeding the realserver are inactive)
and the prompt is returned instantly.
Presumably nfs doesn't allow you to r,w to remote devices (I've never
seen anyone write to /remote_machine/dev/tape by nfs).
I wrote a perlscript which read from a FIFO and wrote to /dev/null. I tried
to write to the named pipe on the realserver from the client, but this hung.
A posting on dejanews said that this wasn't in the nfs protocol either.
(see the Bootdisk-HOWTO).
The ramdisk needs to be large enough to accept the biggest file transferred.
With 64M of realmemory, I made the ramdisk large enough to accept the 32M file
(ie 36M, a bit to spare since I would have to be rm'ing the files by hand as they came
in). Recompile the kernel with the ramdisk (in block devices).
$/sbin/insmod rd rd_size=40000
$/sbin/mke2fs -m 0 -i 2000 /dev/ram0
$mount -t ext2 /dev/ram0 /mnt
/ client2(rw,insecure,link_absolute,no_root_squash)
lvs:/ /mnt nfs rsize=8192,wsize=8192,timeo=14,intr 0 0
Here's the LVS conf file
#lvs_dr.conf for nfs on realserver1
LVS_TYPE=VS_DR
INITIAL_STATE=on
VIP=eth1:110 lvs 255.255.255.255 192.168.1.110
DIRECTOR_INSIDEIP=eth0 director-inside 192.168.1.0 255.255.255.0 192.168.1.255
DIRECTOR_DEFAULT_GW=client2
SERVICE=t telnet rr realserver1 realserver2 #for sanity check on LVS
#to call NFS the name "nfs" put the following in /etc/services
#nfs 2049/udp
#note the 'u' for service type in the next line
SERVICE=u nfs rr realserver1 #the service of interest
SERVER_VIP_DEVICE=lo:0
SERVER_NET_DEVICE=eth0
SERVER_DEFAULT_GW=client
#----------end lvs_dr.conf------------------------------------
Here's the script run on the client to do the copy from the realserver to the client.
It is very similar to the other test scripts.
#!/bin/bash
#run_nfscp.sh
HOST="sneezy" # or LVS
#run this file by doing
# . ./run_nfscp.sh > foo.out 2>&1
for SIZE in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
do
FILE="file.${SIZE}"
echo "file $FILE size $SIZE \n"
#do it twice to flush buffers
#copying from remote machine
cp /${HOST}/usr2/src/temp/lvs/file/${FILE} /dev/null
cp file.26 /dev/null
time -p cp /${HOST}/usr2/src/temp/lvs/file/${FILE} /dev/null
#writing to remote ramdisk
#cp /usr2/src/temp/lvs/file/${FILE} /${HOST}/mnt
#time -p cp /usr2/src/temp/lvs/file/${FILE} /${HOST}/mnt
done
#-----------------------------
~
~
When copying from the client to the finite ramdisk at the realserver end,
this script was run on the realserver, during the copy, to erase files
after they arrived.
#!/bin/sh
PREVIOUS_FILE_SIZE=20
for FILE_SIZE in 21 22 23 24 25 26
do
echo "waiting for file.${FILE_SIZE}"
until [ -e file.${FILE_SIZE} ]
do
sleep 1
done
rm file.1* file.0 file.2 file.3 file.4 file.5 file.6 file.7 file.8 file.9
echo "deleting file.${PREVIOUS_FILE_SIZE}"
rm file.${PREVIOUS_FILE_SIZE}
ls -alFrt file.*
PREVIOUS_FILE_SIZE=$FILE_SIZE
done
#--------------------------------------
Method:
A director on the realserver was mounted onto the client either by forwarding
through the director (in which case the machine is called "realserver")
or by lvs through the director (in which case the machine is called "LVS").
Files of increasing size were copied from the realserver to /dev/null on the client
or from the client to a ramdisk on the realserver (note extra copies as needed to
flush buffers as above).